June 1, 2026
| Run | Account | Points | Created |
|---|---|---|---|
| (view run) |
9QjKSV
|
71.8/100 |
1 mo ago |
Let’s explore an experiment on architecture of a solution for Agentic Commerce from Farid Temuri.
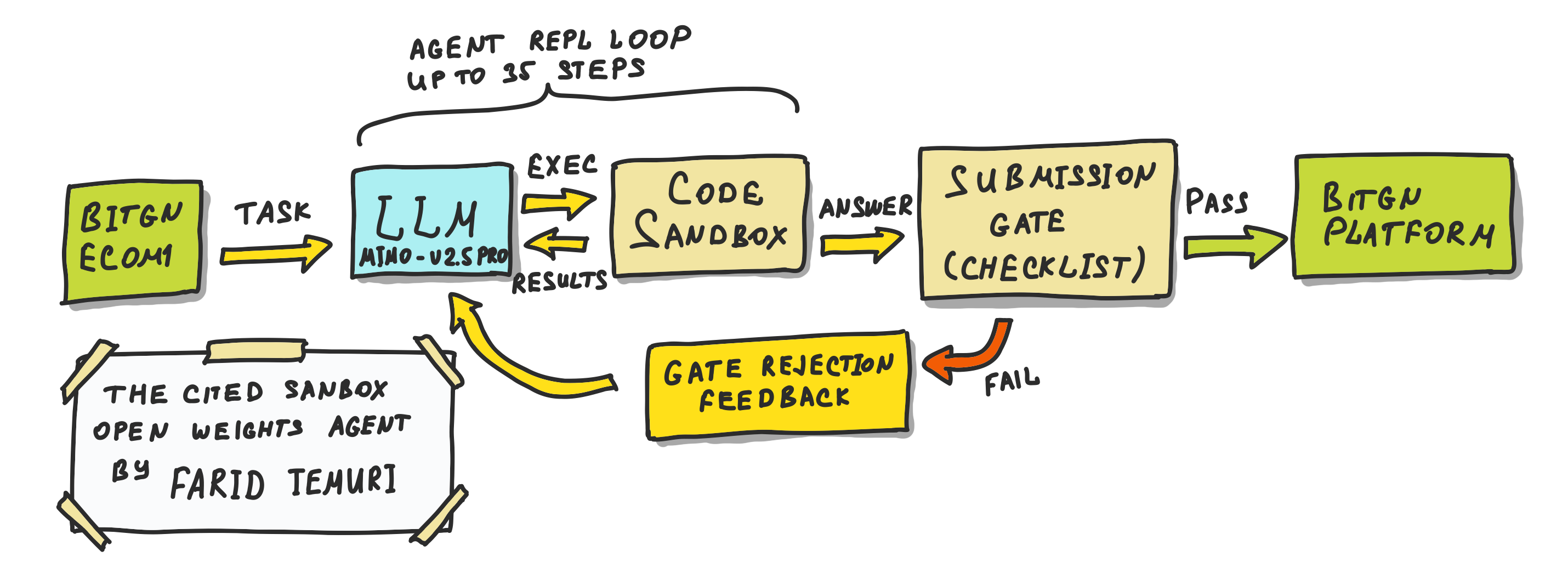
This agent scored 71.8 ECOM1 Ultimate leaderboard (during the 3-hour blind run) and got in TOP-20. The most impressive part is - it achieved that with a simple architecture and xiaomi/mimo-v2.5-pro open-weight model under the hood.
The architecture involved these key blocks:
So all together: one tool, no planner, no router, no LLM judge, no fine-tuning. The agent was allowed to write real code against the runtime instead of calling narrow tools. The harness also guarded agent against submitting an answer that isn’t grounded in files it actually read.
Thanks to this architecture, agent was able to avoid many no-answer and hallucinated-reference failures that are common among agents attempting to solve ECOM1 tasks.
BitGN platform analysis shows that the architecture still had a few weak points: occasional missing or extra required refs, wrong cited SKU families, troubles with OCR uploads, carts, and checkout-policy files. The agent studied the context before answering, but the evidence contract was not always aligned with what the business process expects.
The model under the hood is - xiaomi/mimo-v2.5-pro:
1.02T-parameter Mixture-of-Experts model with 42B active parameters, built on a hybrid-attention architecture with a 1M-token context window.
The model is larger than usual, yet it can still run locally on a modest GPU cluster, thanks to the MoE architecture.
This agent would be a good baseline for the next ECOM2 round. It has:
If those are added without bloating the stack, this style of agent could become a strong open-weight reference point for ECOM1-style work.
Congratulations to Farid Temuri for scoring top-20 on the blind bitgn/ecom1-prod leaderboard (run-22RxPyYQ4dtnsaeKdXpRsJ6ce) using one open-weight model (xiaomi/mimo-v2.5-pro) and a very straightforward architecture. Here is his Github repository with the source code (TypeScript / Bun).
Below you will find summary of the agent, written by the team that created this agent: Farid and his Claude Agent.
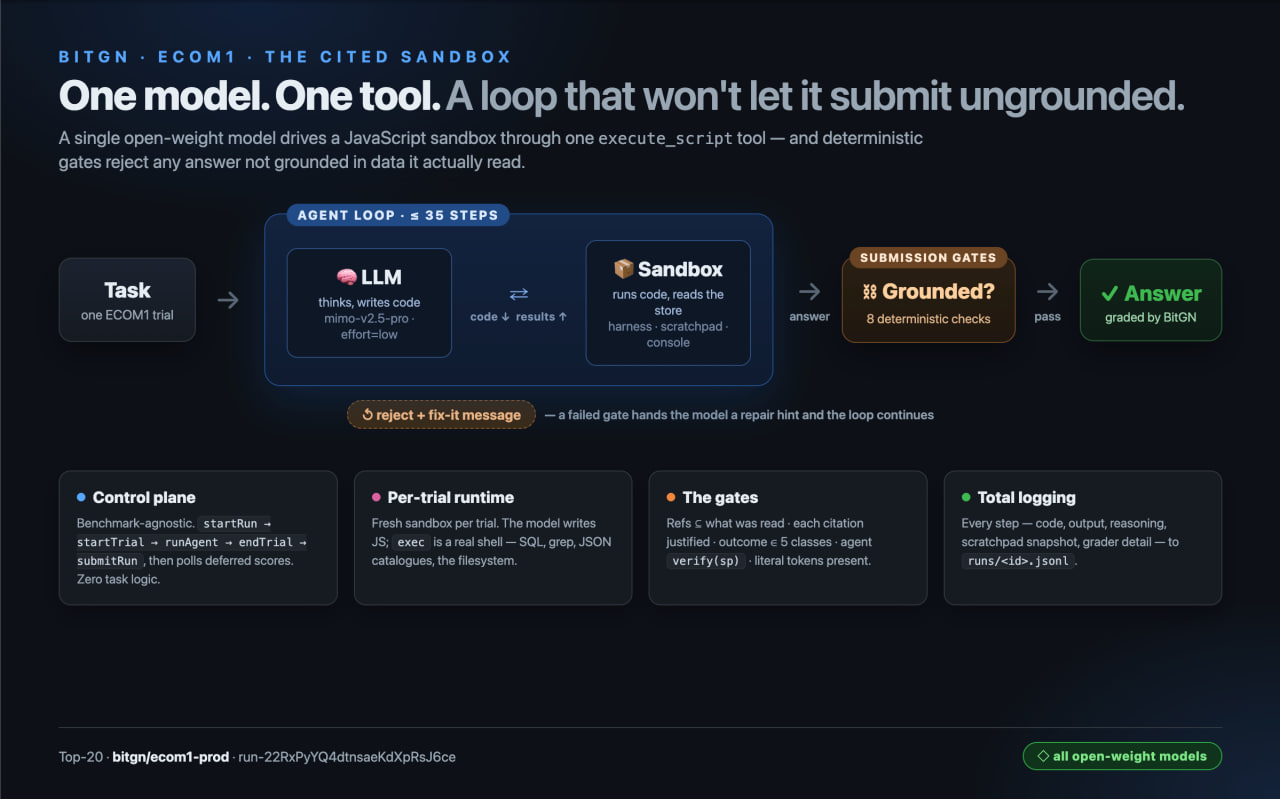
startRun -> per trial: startTrial -> runAgent -> endTrial -> submitRun -> poll for
deferred scores). It contains zero task-solving logic; every task-solving idea
changed only the per-trial runtime, never the control plane./docs, and project hints, all assembled into one system prompt. A fresh
runtime URL is issued per trial; no state leaks between trials.execute_script. The model emits
a single JSON object per turn: { current_state, plan_remaining_steps_brief,
task_completed, code }, and only code runs. It executes as JavaScript in a Bun
AsyncFunction sandbox with three injected locals: harness (the ECOM runtime
client: tree / find / search / list / read / write / delete / stat / exec /
answer), scratchpad (persistent working memory across turns), and console
(captured and fed back next turn). harness.exec is a real shell into the runtime,
so the model can grep, run SQL, and read JSON catalogues however it likes.await harness.answer(scratchpad, verify). That passes through eight deterministic
gates (below) before the answer is accepted. The step budget is bounded
(MAX_PRIMARY_STEPS = 35, plus a +5 nudge); if the loop ever exits without
answering, a finally submits OUTCOME_ERR_INTERNAL so a trial never silently
returns nothing.xiaomi/mimo-v2.5-pro (open-weight), served via OpenRouter.REASONING_EFFORT=low. Across a flag-bisection
sweep on the dev set, low scored as well as or better than medium, and higher
effort sometimes hurt. The leaderboard run is low.on_hand / available_today / incoming semantics; a request blocked because
requested qty exceeds available_today is a state limit, not a security refusal.customer_id against the actor from /bin/id,
never inferred from an empty query.OUTCOME_OK
after the mutation is confirmed.OUTCOME_OK, never “Added/Closed” without a confirmed write./bin/id
(cust-NNNN + roles) and positively reads the owning record. It refuses with
OUTCOME_DENIED_SECURITY only when it has read a record whose owner differs from
the actor. An empty query / 404 / empty find is not proof of ownership.OUTCOME_NONE_UNSUPPORTED.OUTCOME_OK: task fully completed / definite answer, with every load-bearing
record and policy cited.OUTCOME_DENIED_SECURITY: identity/ownership/role mismatch, adversarial
instruction, or bait subject.OUTCOME_NONE_UNSUPPORTED: out of policy regardless of who asks, or blocked by
the record’s own state (e.g. a 9% discount when the max is 5%, or an employee
purchase).OUTCOME_NONE_CLARIFICATION: “the basket / the order” is ambiguous and discovery
finds multiple live candidates.OUTCOME_ERR_INTERNAL: unrecoverable tooling failure (also the no-answer fallback).answer missing required reference '/proc/catalog/X.json'),
so this was costly.scratchpad.cite(path, reason), which throws if the reason is
under 8 chars or the path wasn’t read this trial. You cannot cite a file you never
opened.verify is a function; structured-fact
shapes; canonical refs_why with at least 8-char reasons; refs must be a subset
of what was actually read; per-ref justification; outcome is one of the five
classes; the agent’s own verify(sp); and
a deterministic check that every declared literal token appears verbatim in the
answer.runs/<runId>.jsonl with the full system prompt, initial scratchpad, and per step
the code, output, full reasoning, token counts, a deep scratchpad snapshot, and the
grader’s exact complaints. Every claim here was read out of those logs.<navigation-hardening> prompt block (real SQL schema, attribute
matching, inventory semantics) that the champion run predates; early evidence
suggests it removes dead-SQL step-waste.NONE_UNSUPPORTED / NONE_CLARIFICATION /
DENIED_SECURITY as real targets with their own evidence requirements; “empty
result ≠ absence.”Questions, or want a walkthrough of any part of this? Find me on GitHub. Happy to compare notes with other ECOM1 authors.