June 15, 2026
| Run | Account | Points | Created |
|---|---|---|---|
| (view run) |
BgrMWL
|
71.8/100 |
2 mo ago |
| (view run) |
BgrMWL
|
74.7/100 |
2 mo ago |
In ECOM1, an agent can make the right business decision and still score zero, if it can’t prove its reasoning with the correct grounding references.
The answer has to carry the right outcome code, cite the right evidence, and leave the simulated company in the right state. If the cited record is wrong, or the final state is one enum off, the verifier does not care that the agent basically understood the task. “Basically” is just not good enough for the Agentic Commerce.
Exoskeleton architecture by Ilyas Salikhov approached this problem by taking a smaller LLM, gpt-5.4-mini and designing a verification architecture around it: the model routes the work, while deterministic code enforces evidence, outcome, format, and security contracts.
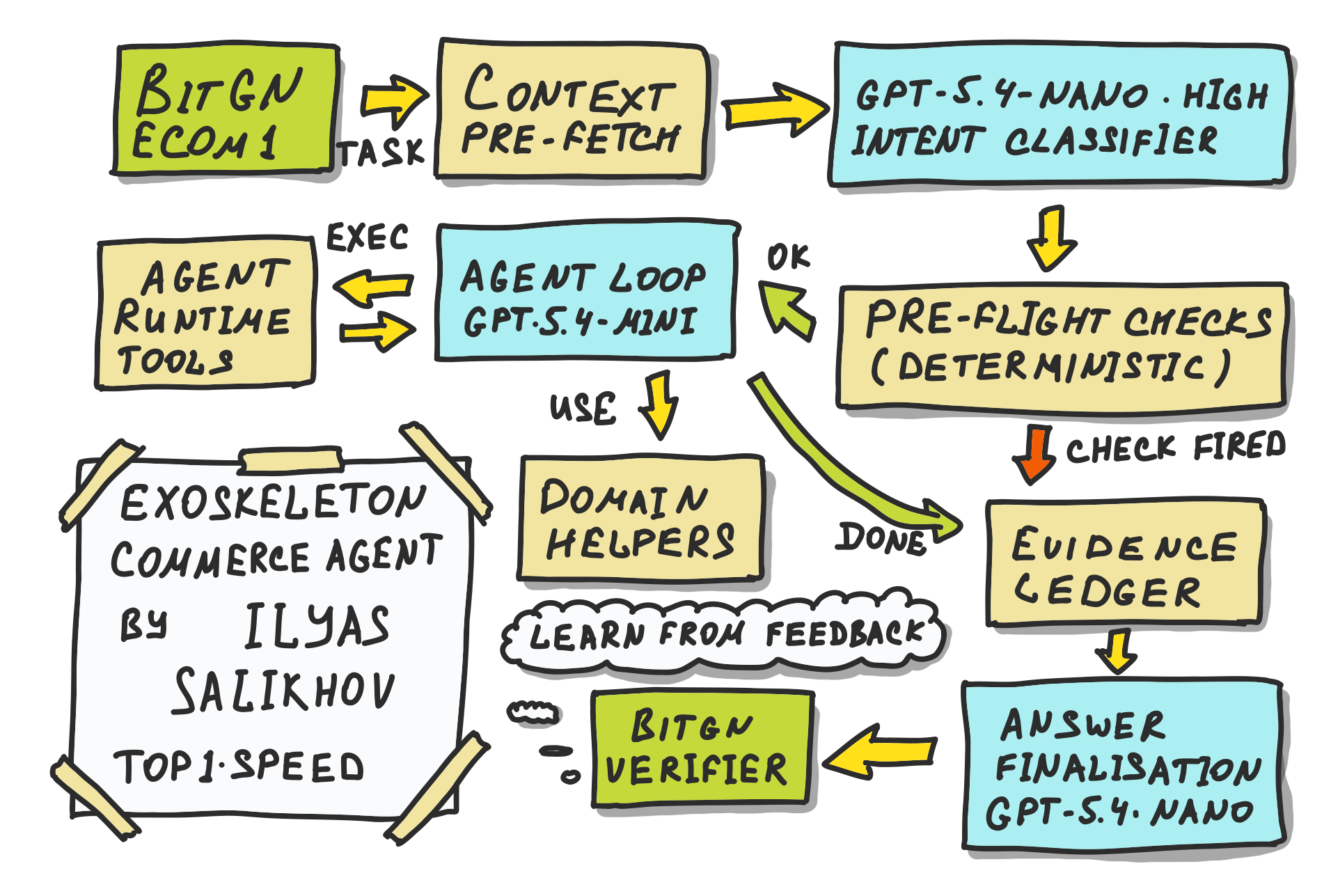
This architecture worked well and fast.
The blind run nominated for Speed, scored 71.8 points with total thinking time of 51 minutes and is TOP1 on that board. Another blind run scored 74.7 points (total thinking time of 42.5 minutes) and is the architecture’s Ultimate entry at #10 overall.
Live PROD leaderboard is the continuing benchmark after the event (not a competition board). At the time of writing, Exoskeleton leads it at 97.4 points!
Exoskeleton treats gpt-5.4-mini mostly as a dispatcher. The model understands the request, chooses tools, and makes the judgment call when judgment is needed.
The surrounding Python code owns the contracts that should not drift:
This hardening did not happen inside the blind run itself. In blind mode the agent cannot see verifier feedback or learn from hidden failures. The improvement loop happened before submission: ECOM1-DEV runs, traces, and heatmaps exposed repeated failure classes.
Once a failure class was predictable enough (wrong refs, unstable fraud logic, unsafe citation, bad answer format, over-broad refusals) Ilyas treated it as a code problem. Those patterns became checks, helpers, or validators that were already present when the blind run started.
TLDR; the recipe: do not ask a small model to remember every rule. Let it route the work. Put the contract in code.
BitGN telemetry data and verifier feedback show that the architecture paid off.
The rail-friendly task types worked well here. Returns handling scored perfectly 8 of 8 perfect tasks in the family in both runs. Policy/control got perfectly 28 of 29 in both. 5 out of 6 discount tasks were solved perfectly, and 4 out of 5 3DS recovery flows as well. These are the task families where deterministic checks, policy helpers, and answer assembly should help.
The Speed winner submission used 19k API calls. The higher-scoring Ultimate run used only 5.5k while finishing faster and scoring higher (so this would in theory make even stronger Speed submission). That is the architecture learning: less wandering through the filesystem, more direct use of startup context, helpers, and known paths.
Now let’s take a look at what went wrong.
Grounding references are the largest failure mode: 17 zero-score misses in the Speed run and 15 in the Ultimate run were clearest as wrong or missing refs (agent didn’t provide correct references). A correct-sounding answer does not matter if the evidence trail is not the one the verifier accepts.
Dispatch was the other visible gap. The Speed run got partial credit on all five dispatch tasks; the Ultimate run fell to four zeroes and one partial. Inventory/OCR stayed weak too - 4⁄5 out of 14 points. These tasks are less about final formatting and more about finding the right facts in the first place.
The architecture by Ilyas Salikhov shows us that a smaller model can be competitive when code carries the verification contract around it.
To copy the core architectural principles of Exoskeleton agent:
Congratulations to Ilyas Salikhov for taking TOP1 on the ECOM1 Speed leaderboard with Exoskeleton, and for publishing the implementation and architecture notes for the rest of the field to learn from.
You can find more detailed read-out from Ilyas in Team Deep Dive.