April 18, 2026
| Run | Account | Points | Created |
|---|---|---|---|
| (view run) |
qVPTKT
|
92.0/104 |
3 mo ago |
| (view run) |
qVPTKT
|
87.0/104 |
3 mo ago |
Operation Pangolin tied for first place in the most demanding part of the BitGN PAC1 blind run, alongside codex-on-rails.
Pangolin is a compact programmable analyst built around a strict checklist, a REPL cycle, and durable memory.
The core of this agent is written in TypeScript. It uses the Anthropic client to leverage the Sonnet model in development (production runs used Opus). Thanks to the lean architecture, a development run costs ~4 USD, while a production run costs ~10 USD.
While the BitGN PAC1 runtime exposes multiple agentic tools, Pangolin gives Claude only one callable tool at the root: execute_code.
Essentially, the LLM is responsible for writing Python code that can then access the PAC1 runtime via the Workspace class. This is not a blank coding sandbox, though: the runner also preloads the workspace tree, current UTC context, a scratchpad that persists across LLM calls, and JSON-serializable Python variables that survive between execute_code iterations.
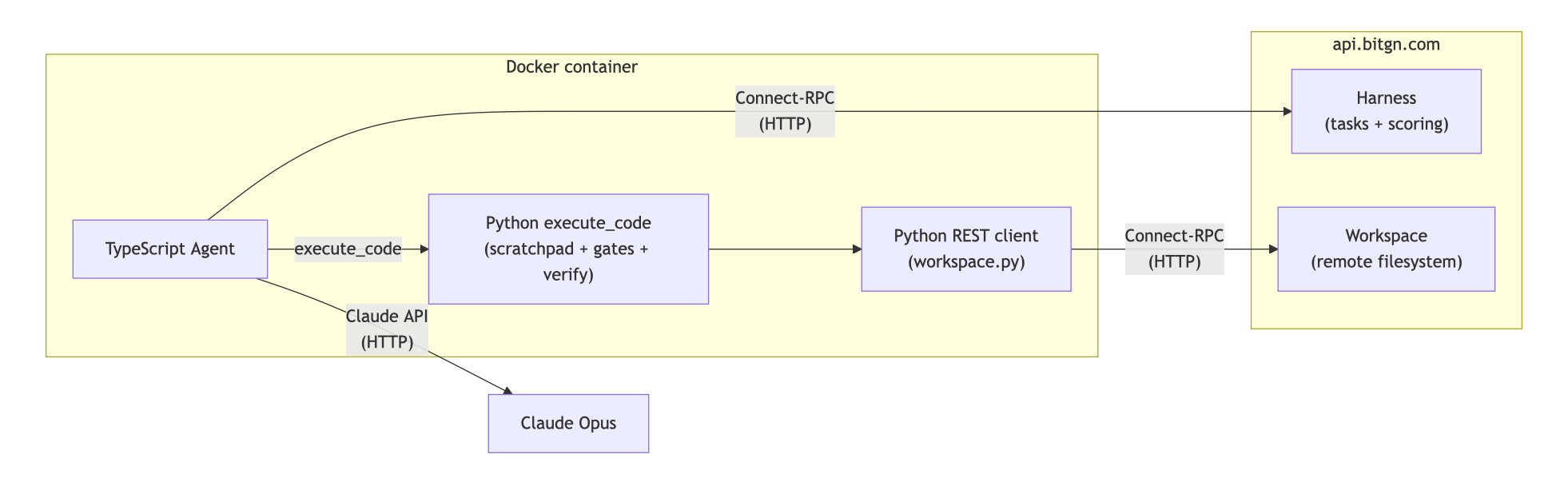
Tool results are returned to Claude, and the loop continues until the code returns a response via ws.answer(scratchpad, verify). The result must also pass a verify gate.
Blind-run artifacts suggest a few weak spots around the handoff between reasoning and code. For example:
t011)t006)t025 or t051)t012, t037)Even with those misses, the solution tied for first on Accuracy and finished first on the Ultimate leaderboard.
To reproduce this architecture in your agent:
Congratulations to Illia Dzivinskyi for scoring 1st place with 87.0 points (shared with codex-on-rails) in the Accuracy Leaderboard of the BitGN PAC1 blind run.
The Accuracy leaderboard is the most challenging leaderboard because it targets absolute precision: participants must blindly pick only one submission out of their runs and hope that it scored high enough.
Operation Pangolin also achieved the best overall score in the Ultimate Leaderboard with 92.0 points.