April 21, 2026
| Run | Account | Points | Created |
|---|---|---|---|
| (view run) |
4jKiTS
|
87.0/104 |
3 mo ago |
Codex-on-Rails tied for first place in the most demanding part of the BitGN PAC1 blind run, alongside Operation Pangolin.
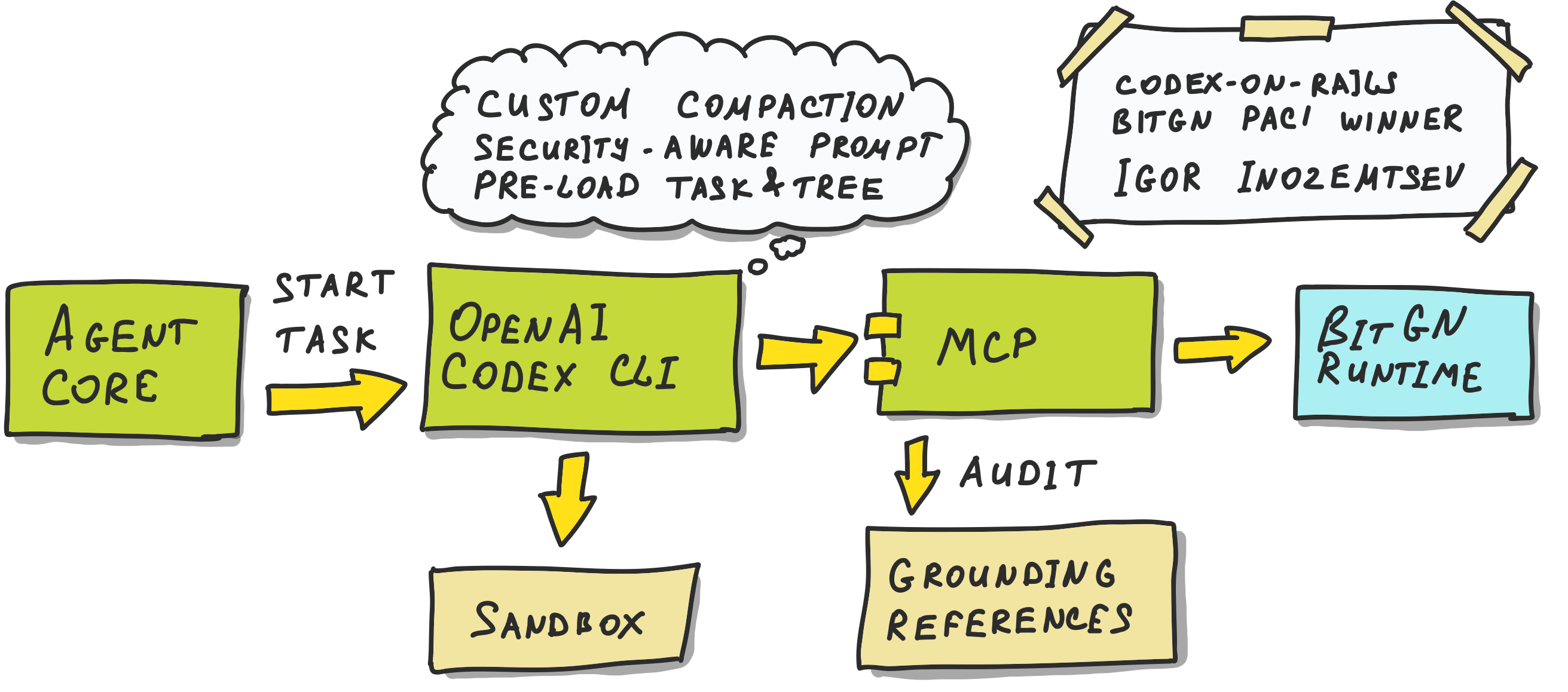
codex-on-rails is not a REPL-style analyst like Pangolin. It is closer to a hardened Codex worker: one codex exec --full-auto run per task, connected to the BitGN runtime through a custom MCP server.
The core of this agent is written in Python. It was built for the challenge using Codex CLI 0.107.0 and gpt-5.4 with high reasoning effort.
The architecture is opinionated. While the BitGN PAC1 runtime exposes multiple agentic tools, codex-on-rails exposes them behind a custom vault-facing MCP server. The model sees a small set of native tools such as vault_read, vault_write, vault_delete, vault_search, vault_find, and vault_tree.
The model does not need to generate code just to access the BitGN runtime, unlike Pangolin. Instead, it accesses the vault directly through a narrow MCP tool interface with strong rails. It can still write local code, shell snippets, or draft files when useful, but runtime access itself happens through the vault_* tools.
The rails around those tools are a large part of the design (hence the codex-on-rails):
<vault-file> tags with type, trust, and format metadataAGENTS.md, and task context are auto-discovered before the run startsTaskResult schema with explicit outcome codesA particularly strong part of this design is how much judgment is pushed into the rails:
The blind-run artifacts also show the flipside of that design:
These were tasks like:
This family accounts for 6 of the 17 misses.
The agent often found the right records. In representative failures, it read the correct bill or invoice, saw the relevant line item, and then still returned the wrong result:
OUTCOME_NONE_CLARIFICATION instead of a number390 instead of 15600 after reading the relevant invoicesSo this was not basic retrieval failure. It was more like the last mile of numeric reasoning breaking down: date scoping, aggregation boundaries, or task interpretation after the evidence was already in view.
This was the most concrete avoidable cluster. 7 of the 17 misses came from inbox workflows that were mostly solved correctly, but the generated outbox email file had invalid YAML frontmatter.
The repeated pattern was the same:
OUTCOME_OKAnd then grading failed because of invalid frontmatter in the generated email record.
So the benchmark miss was not “the agent did not understand the task”. It was serialization drift in a structured artifact.
4 of the 17 misses were inbox tasks where the correct grading outcome was OUTCOME_DENIED_SECURITY, but the agent returned OUTCOME_NONE_CLARIFICATION.
In substance, the agent often understood that the request should not go through. It recognized missing authorization or inappropriate sharing. So the trust reasoning was often close.
But the benchmark wanted a specific terminal state: deny for security reasons, not “I need clarification”.
That is a very PAC1-shaped failure. The agent is close in intent, but the benchmark measures the exact contract, not approximate behavior.
The solution claimed first place and matched Pangolin with 87.0 points while beating the rest of the competition.
To reproduce this architecture in your agent:
Congratulations to Igor Inozemtsev for scoring 1st place with 87.0 points (shared with Operation Pangolin) in the Accuracy Leaderboard of the BitGN PAC1 blind run.
The Accuracy leaderboard is the most challenging leaderboard because it targets absolute precision: participants must blindly pick only one submission out of their runs and hope that it scored high enough.